


Puede la información en el universo ser explicada por procesos naturales que ultimadamente se reducen a partículas subatómicas o tiene una explicación que va más allá de lo material?
Este es el tema del siguiente debate entre Chris Du-Pond (Creyente) y Manuel Mendoza (Ateo).
Dado lo detallado del debate, me limitaré a presentar aquí el discurso de apertura solamente. El resto del debate puede ser descargado en formato pdf en este sitio. Abajo puedes dejarnos tu opinion en la sección de comentarios. !Gracias por participar!
En este debate voy a defender dos contenciones principales.
- Tenemos buenas razones para creer que la naturaleza está imposibilitada para crear información novedosa según los teoremas de conservación de información.
- Aunque mi contención #1 falle, de todos modos se sostiene que el naturalismo es falso dada la imposibilidad del naturalista a ejercitar su “libre pensamiento” para demostrar que la información tiene origen natural.
Para defender la contención #1 utilizaré el siguiente argumento lógico.
-
La información ya sea, tiene origen sobrenatural o tiene un origen natural.
-
La información no tiene origen natural.
-
Por lo tanto, la información tiene origen sobrenatural.
Para defender la contención #2 utilizaré el siguiente argumento lógico: 1
-
Si el naturalismo es verdad, el alma-mente inmaterial humana no existe.
-
Si el alma-mente no existe, el libre albedrío libertario no existe.
-
Si el libre albedrío libertario no existe, la racionalidad y el conocimiento no existen.
-
La racionalidad y el conocimiento existen
-
Por lo tanto, el libre albedrío libertario existe.
-
Por lo tanto, el alma existe.
-
Por lo tanto, el naturalismo es falso.
La mejor explicación para la existencia del alma es Dios.
El primer argumento es un silogismo disyuntivo válido y el segundo es de la forma:
- N → ¬ A
- ¬ A → ¬ LAL
- ¬ LAL → ¬ R & ¬ C
- R & C
- R & C → LAL
- LAL → A
- A → ¬ N
Ambos argumentos son válidos, y si las premisas se sostienen entonces las conclusiones se sostienen necesariamente. Así que procederé a demostrar las premisas.
Alternamente, Manuel tendrá que demostrar que alguna de las premisas en mis dos argumentos es inválida ya que un solo argumento es suficiente para mostrar que el naturalismo es falso y por lo tanto incapaz de generar información. Pero no sólo eso; Manuel no sólo debe demostrar que mis argumentos fallan sino que tendrá que erguir un argumento propio que muestre la forma en que la información puede ser generada por procesos naturales. Una cosa es mostrar que la información NO tiene origen supernatural eliminando 2 argumentos, y otra muy distinta es mostrar que la información tiene origen natural.
Aquí comenzaré justificando las premisas de la contención #2:
Según el diccionario Webster una definición simple de información es:
Conocimiento que se obtiene acerca de alguien o de algo: hechos o detalle acerca de algún tópico”. De forma más detallada la define como “la comunicación o recepción de conocimiento o inteligencia”. Aquí el problema para el naturalista, es que si el naturalismo es verdad, es imposible recibir o transmitir información y la empresa de obtener conocimiento es una simple ficción. Esto se demuestra por el argumento del “libre pensador.2
Premisa 1: Si el naturalismo es verdad, el alma-mente inmaterial humana no existe. Este hecho es aceptado por los naturalistas, así que no requiere justificación.
Premisa 2: Si el alma-mente no existe, el libre albedrío libertario no existe.
Esto equivalente a,
«Si todo lo que existe es lo natural, entonces todo lo que existe es causalmente determinado a través de las leyes naturales y por cosas y efectos fuera del control humano».
Esto es aceptado por conocidos naturalistas como Richard Dawkins, Stephen Hawkin, Sam Harris, etc.
En un diálogo acerca del determinismo científico y moralidad, Dawkins afirmó:
“Ninguno de nosotros dice: ‘Oh bueno, no pudo evitar hacerlo; así estuvo determinado por sus moléculas… Pero tal vez deberíamos’.
Cuando se le preguntó que si esta perspectiva era inconsistente con el ateísmo y naturalismo, Dawkins contestó:
“De cierto modo, sí. Pero es una inconsistencia con la que tenemos que vivir, de otra forma la vida sería intolerable”.3
Dawkins admite que para vivir feliz como ateo se necesita cree en una “mentira blanca” y en un estado de auto-engaño.
Stephen Hawking está de acuerdo:
Es difícil imaginar como el libre albedrío puede operar si nuestro comportamiento está determinado por leyes físicas, así que parece que no somos más que máquinas biológicas y el libre albedrío es un espejismo.4
Afirma también que nuestro comportamiento está determinado al igual que las orbitas de los planetas.
Sam Harris se une al coro:
“El libre albedrío es una ilusión. Nuestras voluntades no son propias”.5
Esta negación del libre albedrío nos lleva al siguiente punto.
Premisa 3: Si el libre albedrío libertario no existe, la racionalidad y el conocimiento no existen.
Esto incluye pensamientos, y transmisión de información. Las decisiones libres de Manuel de usar las leyes de la lógica, y su capacidad de analizar la información que he plasmado en símbolos decodificables por sus neuronas no son más que una mera ilusión. Las ideas, procesamiento de información, y obtención de conocimiento son simplemente determinadas por las leyes de la física y la química. Si el naturalismo es verdad, no hay libre albedrío en nuestras acciones, incluyendo la noción que un argumento es mejor que otro.
El determinismo prácticamente se autodestruye: Si uno llega a creer que el determinismo (que toda acción es producto de procesos anteriores naturales) es verdad, uno tiene que concluir que la única razón por la que llegó a esa conclusión es porque estaba determinado a hacerlo. El naturalista debe aceptar que la razón por la que viene a aceptar el determinismo fue, en sí, determinada. A fin de cuentas, es difícil ver como uno puede afirmar el determinismo racionalmente, dado que tal afirmación se auto-destruye.
La conclusión de todo esto es que, la capacidad de discernir leyes de lógica, matemáticas o de tener estados de intencionalidad dependen del libre albedrío, pero dado que el libre albedrío simplemente no existe, la capacidad de discernir, transmitir conocimiento e información tampoco existen porque requieren del uso de la voluntad. Quisiera aquí hacer notar que en el momento en que Manuel comience a usar su capacidad de razonamiento para debatir éste punto, estará tácitamente afirmándolo (y cediendo el debate) porque para argumentar es necesario poder discernir: cosa imposible si somos robots de carne. Si Manuel objeta a esto, yo le preguntaría: ¿Si todos tus pensamientos están predeterminados, entonces cómo SABES que tus pensamientos predeterminados son verdaderos? Lo único que el naturalista puede hacer es PRESUPONER que sus pensamientos predeterminados son correctos (una falacia de petición de principio). Y cualquier argumento basado en una falacia no es argumento válido.
Premisa 4: La racionalidad y el conocimiento existen.
Más aún, cuando Manuel haga uso de sus facultades mentales, lea los argumentos por medo del procesamiento de los SÍMBOLOS en este escrito, su mente convierta los DATOS en INFORMACIÓN, y haga uso de su libre albedrío (nadie lo está obligando a debatir) para responder, estará afirmando esta premisa #4.
Y así, si el naturalismo es verdad, no lo podríamos saber porque no tendríamos libertad para procesar ese tipo de información o ningún tipo de información para tal caso.
Para mostrar que la información tiene un origen natural, Manuel tiene que razonar y usar su libre albedrío lo cual elimina el naturalismo.
Vayamos ahora a mi primera contención:
1) Tenemos buenas razones para creer que la naturaleza está imposibilitada para crear información novedosa según los teoremas de conservación de información.
Para defender la contención #1 utilizaré el siguiente argumento lógico.
- La información ya sea, tiene origen sobrenatural (no material) o tiene un origen natural.
- La información no tiene origen natural.
- Por lo tanto, la información tiene origen sobrenatural.
Este argumento acumula la evidencia del argumento anterior haciendo del naturalismo algo inverosímil.
Premisa 1: La información ya sea, tiene origen sobrenatural o tiene un origen natural Creo que esta premisa no es controversial dado el principio del medio excluido.
Premisa 2: La información no tiene origen natural.
Aquí es donde desarrollaré la mayor parte de este argumento. Quisiera aclarar que mi argumento (basado en trabajo de Dembski) incorpora principios de matemáticas y teoría probabilística aceptada por todos los departamentos de ciencias computacionales universitarios. Manuel tendrá que demostrar aquí porque las matemáticas fallan una vez que se postulen los teoremas de conservación de información formalmente.
En Steps towards life, Manfred Eigen identifica lo que considera el problema central al que se enfrenta la investigación sobre el origen de la vida: “Nuestra tarea consiste en encontrar un algoritmo, una ley natural que nos conduzca hasta el origen de la información”.6 Eigen solo tiene la mitad de la razón. Para determinar cómo empezó la vida, ciertamente es necesario comprender el origen de la información. Pero incluso entonces, ni el algoritmo ni las leyes naturales son capaces de producir la información. El gran mito de la biología evolutiva moderna es que la información puede conseguirse por nada, sin recurso a la inteligencia.7 Es este mito el que busco refutar, pero para hacerlo tendré que dar una explicación de la información relevante para la biología. 8
La intuición fundamental que subyace a la información no es, como a veces se piensa, la transmisión de señales a través de un canal de comunicación, sino más bien, la actualización de una posibilidad para excluir otras. Como dice Fred: “la teoría de la información identifica la cantidad de información asociada con, o generada por, la ocurrencia de un suceso (o la realización de un estado de sucesos) con la reducción de la incertidumbre, la eliminación de posibilidades, representadas por ese evento o estado de sucesos”.9 Sin duda, cuando las señales se transmiten a través de una canal de comunicación, se actualiza una posibilidad para excluir otras, es decir, la señal que fue transmitida para excluir aquellas que no lo fueron. Pero esto es sólo un caso especial. La información, en primer lugar, presupone no un medio de comunicación sino de contingencia. Robert Stalnaker ha dejado claro este punto: “el contenido requiere contingencia. Aprender algo, adquirir información, es descartar posibilidades. Comprender la información transmitida en una comunicación es saber qué posibilidades serían excluidas por su verdad”.10
Para que haya información, debe haber una multiplicidad de posibilidades distintas, cualquiera de las cuales podría suceder. Cuando una de estas posibilidades acontece y las otras son descartadas, la información se actualiza. Ciertamente, la información en su sentido más general puede definirse como la actualización de una posibilidad y la exclusión de las otras (obsérvese que esta definición comprende tanto la información sintáctica como la semántica).
Así podemos hablar de la información inherente a obtener cien caras de una vez con una moneda no trucada, incluso cuando este suceso nunca sucede. No hay problema con esto. En situaciones contrafácticas la definición de información necesita ser aplicada de manera contrafáctica. Así, al considerar la información inherente a obtener cien caras de una vez con una moneda no trucada, tratamos este suceso o posibilidad como si hubiera sido actualizada. La información necesita ser referenciada no sólo al mundo real sino, de manera cruzada, a todos los mundos posibles.
¿Cómo se aplica la información a la biología o, de manera más general, a la ciencia? Para hacer de la información un concepto útil para la ciencia necesitamos hacer dos cosas:
- Poder medir la cantidad información.
- Introducir una distinción crucial, entre información específica y no específica.
Para los teóricos de la información, la manera más conveniente de medir información es en bits. Cualquier mensaje enviado a través de un canal de comunicación puede transformarse en una ristra de ceros y unos. Por ejemplo, el código ASCII emplea cadenas de ocho ceros y unos para representar los caracteres de una máquina de escribir, de modo que las palabras y frases son cadenas de cadenas de tales caracteres. De igual manera, todas las comunicaciones pueden ser reducidas a transmisiones de secuencias de ceros y unos. Dada esta reducción, la manera obvia en que los teóricos de la comunicación miden la información es en el número de bits transmitidos por el canal de comunicación. Y ya que el logaritmo negativo de la base 2 de una probabilidad corresponde al número medio de bits necesarios para identificar un evento de esa probabilidad, el logaritmo en base 2 es el logaritmo canónico de los teóricos de la comunicación. Por tanto, definimos la medida de la información (I) en un suceso de probabilidad p como –logp.11
Consideremos también que la probabilidad de que se den dos eventos cualesquiera A y B conjuntamente es igual al producto de las probabilidades de A y B tomadas individualmente. De manera simbólica, P(A&B)=P(A) x P(B). Dada nuestra definición logarítmica de información, podemos afirmar que P(A&B)=P(A) x P(B) si y sólo si I(A&B)=I(A) x I(B).
Pero, y ¿qué si los eventos A y B están correlacionados? Esto se puede definir como información condicional de B dado A, o sea I(B/A) de forma que si A no contribuye nada de información adicional entonces I(B/A)=I(B). Así, podemos deducir:
I(A&B) = I(A) + I(B/A) (*)
La fórmula (*) es de carácter general, reduciendo a I(A&B) = I(A) + I(B) cuando A y B son probabilísticamente independientes (en cuyo caso P(B/A) = P(B) y entonces I(B/A) = I(B)).
La fórmula (*) afirma que la información en A y B conjuntamente es la información en A más la información en B que no está en A. Por lo tanto, la cuestión es determinar cuanta información adicional de B contribuye a A.
Por ejemplo, ¿genera nueva información un programa de computador llamado A al producir nuevos datos denominados B? Los programas de ordenador son totalmente determinísticos, de manera que B es totalmente determinado por A. Se sigue que P(B/A) = 1, y así I(B/A) = 0 (el logaritmo de 1 es siempre 0). De la fórmula (*) se sigue por tanto que I(A&B) = I(A), y por consiguiente la cantidad de información en A y B conjuntamente no es más que la cantidad de información en A por sí misma.
¿Funciona esto, por ejemplo con dos cadenas de información idénticas como lo son 2 copias idénticas de Don Quijote? En términos de teoría de información diríamos que I(B/A)=0 y en temimos de probabilidad que P(B/A)=1 ya que la segunda copia del quijote es totalmente redundante y no aumenta la cantidad de información.
Para medir información, (su grado de complejidad) se puede usar la formula: Dado un suceso A de probabilidad P(A), I(A)= -log2.P(A) mide el numero de bits asociados a la probabilidad P(A). Por lo tanto, el grado de COMPLEJIDAD DE INFORMACION aumenta a medida que I(A) aumenta o a medida que P(A) decrece.
Para introducir el concepto de CONSERVACIÓN de información, usemos el ejemplo de simulaciones como el programa WEASEL de Dawkins, o AVIDA, o Tierra, que pretenden demostrar el paradigma neo-Darwinista de “introducción” de información de manera NATUAL. El problema es que estos programas acaban contrabandeando información en sus algoritmos tácitamente demostrando que la información debe ser introducida por un programador inteligente. Estos programas se aprovechan de la ignorancia de la forma en que funciona la información. La información de CONTRABANDO será llamada INFORMACIÓN ACTIVA. La información no se materializa mágicamente; solo se produce de una mente inteligente o es movida de un lado a otro por procesos naturales. Pero los procesos naturales y los procesos Darwinianos en particular no crean información. La INFORMACIÓN ACTIVA nos permite apreciar este hecho:
La INFORMACIÓN ACTIVA rastrea la diferencia en información entre una búsqueda a ciegas (blind search), a lo que llamamos la BÚSQUEDA ALEATORIA (null search) y aquella búsqueda que hace un mejor trabajo de encontrar un objetivo (T), a la que llamaremos BÚSQUEDA ALTERNA.
Consideremos entonces una búsqueda del objetivo T en un espacio de búsqueda finito Ω. La búsqueda de T comienza sin ningún conocimiento estructural especial del espacio de búsqueda que pudiera facilitar el encontrar a T. El principio de Bernoulli de razón insuficiente se aplica y por lo tanto estamos en nuestro derecho epistémico de asumir que la distribución de probabilidades sobre Ω es uniforme, con probabilidad de T igual a p=|T|/|Ω|, donde |*| es la cardinalidad de *.
Y entonces aquí, es lógico que la probabilidad p sea tan pequeña por ser una búsqueda de T a ciegas (aleatoria) en el espacio Ω (vg. Una búsqueda de T en Ω de manera aleatoria) que es extremadamente improbable que tenga éxito. El éxito demanda que, en lugar de una búsqueda aleatoria o a ciegas, se ejecute una búsqueda alterna S que tenga éxito con una probabilidad q que sea considerablemente mayor que p. P captura la dificultad inherente de encontrar T a ciegas mientras que q captura la dificultad de encontrar T con una búsqueda alterna. Y aquí la pregunta obligada es:
¿Cómo es que la búsqueda aleatoria o a ciegas que localiza a T con probabilidad p dio lugar a la búsqueda alterna S que localiza a T con probabilidad q?
En el programa WEASEL de Dawkins, se empieza con una búsqueda a ciegas con probabilidad de éxito de aproximadamente 1x10exp40. Esto es p. Luego implementa una búsqueda alterna S (el algoritmo evolutivo) cuya probabilidad de éxito en una docena de iteraciones es cercana al 1. Esto es q. Según Dawkins, con esto queda demostrado el poder de los procesos Darwinianos cuando que lo único que ha hecho es migrar el problema. Al introducir una búsqueda alterna con probabilidad q de éxito, Dawkins incurre en un costo de probabilidad p de encontrar la función de búsqueda correcta, lo cual coincide (no es coincidencia por cierto) con la improbabilidad original de una búsqueda ciega para encontrar T. El problema de información que Dawkins buscaba resolver queda sin solución. Simplemente ha contrabandeado información de su mente inteligente por medio de un algoritmo más eficiente.
Formalicemos este problema matemáticamente usando bases logarítmicas de medición de información. Nótese que todos los logaritmos están en base 2.12
Definamos INFORMACIÓN ENDOGENA IΩ como –log(p), que mide la dificultad inherente de una búsqueda a ciegas (aleatoria) del espacio Ω para localizar T.
Definamos INFORMACIÓN EXOGENA Is como –log(q), que mide la dificultad de la búsqueda alterna S para localizar a T.
Finalmente, definamos INFORMACIÓN ACTIVA I+ como la diferencia entre INFORMACIÓN ENDÓGENA y EXÓGENA: I+ = IΩ – Is = log(q/p). Por lo tanto, la INFORMACIÓN ACTIVA mide la información que debe ser agregada (por eso el signo de + en I+) a una búsqueda aleatoria para aumentar la probabilidad de una búsqueda alterna por un factor de q/p.
Los programas evolutivos como WEASEL de Dawkins, AVIDA de Adami, TIERRA de Ray, y EV de Schneider son todas BÚSQUEDAS ALTERNAS. Por consiguiente, mejoran el patrón de búsqueda sobre una búsqueda aleatoria aumentando la probabilidad de éxito en localizar un objetivo T remplazando una búsqueda IΩ con una búsqueda Is ignorando la INFORMACIÓN ACTIVA I+ agregada por el programador.
Ahora pues, la importancia clave los teoremas de CONSERVACIÓN DE INFORMACIÓN yacen en que demuestra formalmente el flujo de información externamente aplicado a una búsqueda para aumentar su probabilidad de éxito. En otras palabras, estos teoremas demuestran que la mejora en la facilidad de búsqueda, representada por Is que suplanta a IΩ, se debe PAGAR en, términos de información, y el costo es I+ = IΩ – Is.
No solo eso, la INFORMACIÓN ACTIVA representa el nivel ÓPTIMO de información que se debe pagar por mejorar una búsqueda.
Generalizando el caso en que una búsqueda puede consistir en un numero M de consultas, el teorema puede generalizarse matemáticamente:
DEMOSTRACION: Sea Ω = {x1, x2, …, xK, xK+1, …, xM} de tal forma que T = {x1, x2, …, xK} y sea Ω´ = {y1, y2, …, yL, yL+1, …, yN} de tal forma que T´ = {y1, y2, …, yL}. Entonces p = K/M y q = L/N y |F| = MN. Usando el teorema binomial se deriva que el número de funciones en F que corresponden a L elementos de Ω´ en T en los elementos restantes de Ω´ en Ω\T es
![]()
De aquí, a su vez se deriva que el número de funciones F que corresponden a L o más elementos de Ω´ en T y los elementos restantes de Ω´ en Ω´\T
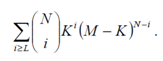
Ahora, si dividimos esta cantidad por el número de elementos en F, es decir MN, obtenemos
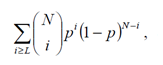
que no es más que una distribución aleatoria binomial acumulativa con parámetros N y p. Es también la probabilidad de T. Dado que la media de tal variable aleatoria es Np ya que q=L/N, se deriva que
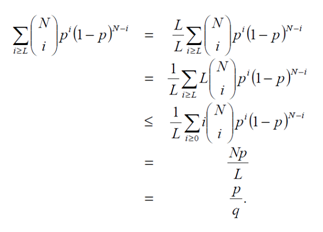
Se deriva entonces que –log(|T|/|F|) está delimitado por la INFOMRACIÓN ACTIVA I+ = log(q/p). Y Esto DEMUESTRA el teorema.
El teorema de conservación de información demostrado anteriormente es probablemente el teorema de conservación de información más básico. Y muestra que al construir una búsqueda alternativa que mejore una búsqueda por encima de una búsqueda aleatoria debe pagar esa mejora en términos no menores de INFORMACIÓN ACTIVA.
Dembski luego desarrolla y DEMUESTRA MATEMÁTICAMENTE tres teoremas adicionales de CONSERVACIÓN de INFORMACIÓN con sus debidas comprobaciones.13
Para los amables lectores, una definición más simple de los teoremas:
El aumentar la probabilidad de éxito de una búsqueda no hace nada para facilitar la llegada a la meta de la misma, y podría en efecto complicarla una vez que se toma en cuenta el costo necesario para aumentar la probabilidad de éxito. La búsqueda es costosa y tal costo debe pagarse en términos de información.
Las búsquedas son exitosas, no porque generan información de la nada sino que toman ventaja de información existente. La información que conlleva a la búsqueda exitosa no admite atajos, solo atajos aparentes que se deben pagar de lleno en otra parte.14
Podemos concluir, entonces, que la información encontrada en el material genético no puede ser creada por procesos evolutivos naturales si dada información no se encontraba ahí anteriormente. Así demostrando el valor de verdad de la premisa 2:
- La información no tiene origen natural
Dada mi contingencia inicial en forma de silogismo, concluimos pues, que la información debe tener un origen sobrenatural (no material).
- La información ya sea, tiene origen sobrenatural o tiene un origen natural.
- La información no tiene origen natural.
- Por lo tanto, la información tiene origen sobrenatural.
Para que Manuel tenga éxito en el debate, primero tendrá que mostrar porque mis dos contingencias son probablemente falsas y en su lugar mostrar un argumento a favor del origen NATURAL de la información genética.
Gracias a todos los que siguieron el argumento hasta aquí.
Aquí puedes descargar el debate completo.
CD
- Este es un argumento lógico desarollado por Tim Stratton. El argumento completo en ingles se puede accessar en http://freethinkingministries.com/freethinking-atheists-are-oxymorons/. ↩
- Ver: http://www.merriam-webster.com/dictionary/information ↩
- Logan Gage, Who Wrote Richard Dawkins‘s New Book?, evolutionnews.org, October 28, 2006. Recuperado de: http://www.evolutionnews.org/2006/10/who_wrote_richard_dawkinss_new002783.html ↩
- Stephen Hawking, The Grand Design, (New York: Bantam Books, 2010), 32. ↩
- Sam Harris, Free Will, (New York: Free Press, 2012), 5. ↩
- Manfred Eigen, Steps towards life: Perspective on Evolution, (Oxford: Oxford University Press, 1996), 12. ↩
- Énfasis añadido. ↩
- El Crédito de los siguientes parrafos se le debe totalmente al Dr. William Dembski por su tabajo en los conceptos presentados. Una traducción completa disponible puede accesarse en: http://www.oiacdi.org/articulos/DI_como_teoria__informacion.pdf. Su trabajo original está disponible en William Dembsli, Intelligent Design as a Theory of Information, An Interdisciplinary Conference at the University of Texas, Discovery Institute, http://www.discovery.org/a/118, (accesado Noviembre 7, 2016). ↩
- Fred Dretske, Knowledge and the Flow of Information, (Cambridge, Mass.: MIT Press, 1981), 4. ↩
- Robert Stalnaker, Inquiry, (Cambridge, Mass.: MIT Press, 1984), 85. ↩
- Véase Claude Shannon y W. Weaver, The Mathematical Theory of Communication, (Illinois: University of Illinois Press, 1949); R. W. Hamming, Coding and Information Theory, 2nd edition (Englewood Cliffs, N. J.: Prentice-Hall, 1986) o cualquier introducción matemática a la teoría de la información. ↩
- El siguiente argumento consistente en postular los teoremas de conservación de información son, totalmente el fruto del trabajo de William Dembski y Robert J. Marks II. Su argumento formalizado y publicado se puede accesar en William A. Dembski and Robert J. Marks II, «LIFE’S CONSERVATION LAW: Why Darwinian Evolution Cannot Create Biological Information» in Bruce Gordon and William Dembski, editors, THE NATURE OF NATURE (Wilmington, Del.: ISI Books, 2009). La version en linea se puede accesar en http://www.evoinfo.org/publications/lifes-conservation-law/. ↩
- Para ver las demostraciones completas: William A. Dembski y Robert J. Marks II, «LIFE’S CONSERVATION LAW: Why Darwinian Evolution Cannot Create Biological Information» en Bruce Gordon and William Dembski, editores, THE NATURE OF NATURE (Wilmington, Del.: ISI Books, 2009). La version en linea se puede accesar en http://www.evoinfo.org/publications/lifes-conservation-law/. ↩
- William Dembski, Being as Communion: A Metaphysics of Information (Burlington, VT: Ashgate Publishing Ltd, 2014), Kindle 3864. ↩
Enriquecedor desde ambos puntos de vista, mas como lector quisiera plasmar la percepción que de buenas y a primeras tuve al leer ambas intervenciones (no lo hubiese hecho pero por mi libre albedrío elegí hacerlo jaja) paradojicamente las intervenciones de Manuel me recordaron un poco al adoctrinamiento «religioso» que afecta a tantos en el mundo y cuya defensa al final se limita a «repetir» una y otra vez ideas preconcebidas y hasta cierto punto prejuiciosas en vez de buscar con buen ánimo una aclaración lógica y racional respecto al tema en cuestión, algo que desgraciadamente se está volviendo tan común entre personas «ateas» Un gran debate, felicitaciones, impulsa la búsqueda de la razón en lo que «no se ve» saludos.
Gracias por leer Diego y gracias por tu comentario. Espero que la verdad haya salido a flote. Ese era el propósito finalmente. Saludos!! CD
Chris su pond,En primer lugar me gustaría felicitarlo por el debate enriquecedor que ofreció,Pero me surgieron algunas dudas y me gustaría su opinión,Con respecto a el supuesto teorema de la conciencia del físico penrose,y la supuesta existencia del libre albedrío en la mecánica cuentica,Muchos canales de física,Opinan que el libre albedrío es posible atraves de esta,Entre ellas están,C de ciencia,Cfracture,Date un voltio,etc,tambien leí que un premio Nobel de química quería postular la existencia de una alma material,Meustaría su opinion,Saludod
Me alegra que haya sido de bendición!
En realidad fue un debate interesante y los disfruté aunque entiendo que no es para todos por el nivel tecnico.
En cuanto a Penrose: no sé exactamente cual es su posición. Lo escuche mencionar lo mismo en un debate pero no ha proporcionado mucho detalle pero él mismo admite que la ciencia está muy lejos de descifrar el surgimiento de la conciencia y de una comprensión profunda del Libre Albedrío.
En estos temas, recomiendo leer al Dr. JP Moreland. Tiene un libro llamado «Soul» donde habla a más profundidad de estos temas.
Saludos!
CD